IEEE Transactions on Signal and Information Processing over Networks dergisinde yayınlanan “Graph Reseptive Transformer Encoder (GRTE) for Text Classification” başlıklı en son makalemizi paylaşmaktan mutluluk duyuyoruz!
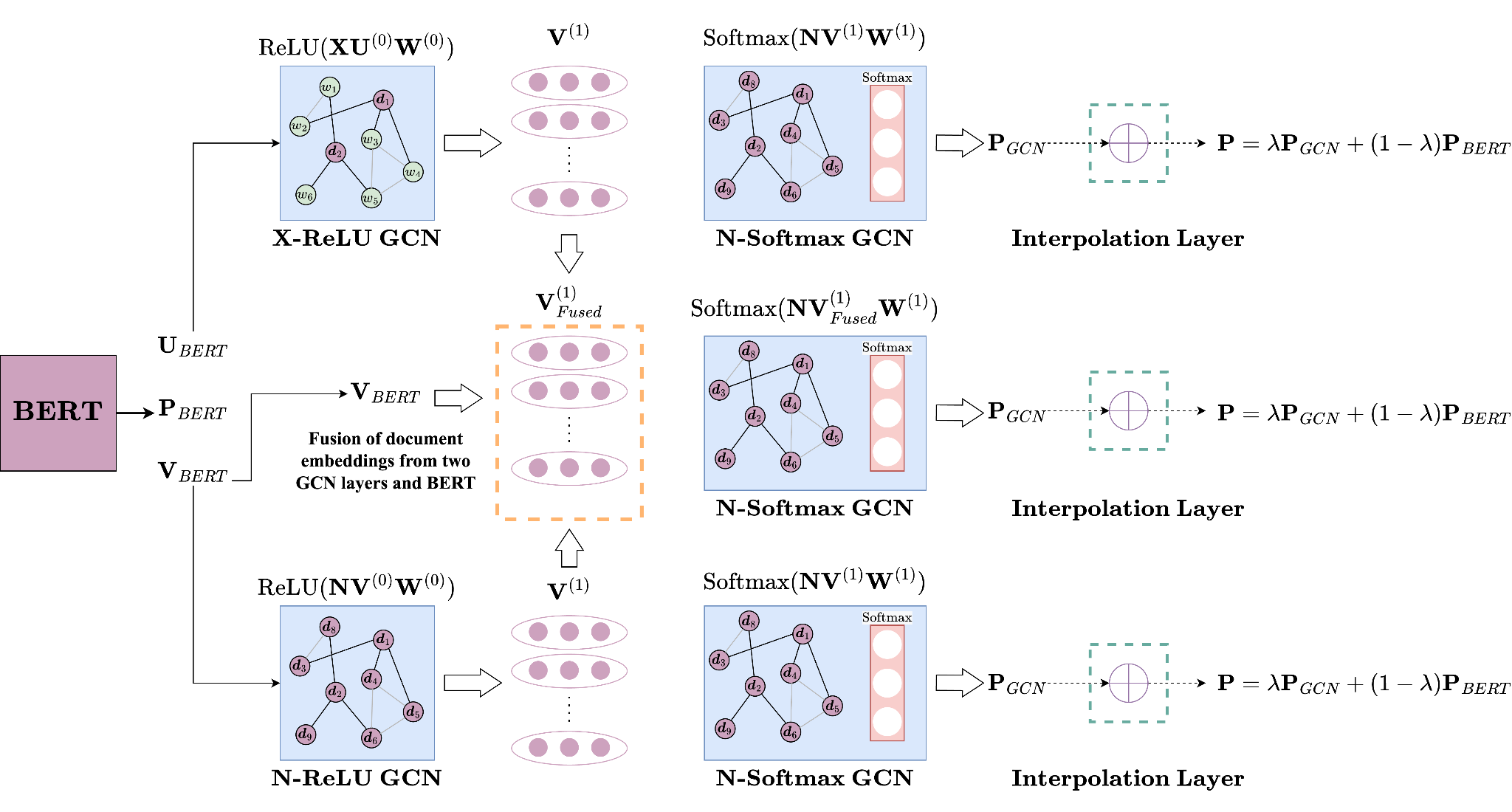
Yeni yaklaşımımız, metin sınıflandırması için dönüştürücülerin dikkat mekanizmalarındaki sınırlamaları ele almak amacıyla grafik sinir ağlarını (GNN’ler) büyük ölçekli önceden eğitilmiş modellerle birleştirir. GRTE, metinleri grafikler halinde temsil ederek küresel ve bağlamsal bilgileri alır, son teknoloji modellere kıyasla önemli performans iyileştirmeleri ve ~100 kata kadar hesaplama tasarrufu sunar.
Daha fazla ayrıntı için makaleye göz atın!
#NLP #TextClassification #Transformer #GNN #GRTE #TSIPN #IEEE
Makale: https://ieeexplore.ieee.org/document/10477516
Kod: https://github.com/koc-lab/grte
Özet:
By employing attention mechanisms, transformers have made great improvements in nearly all NLP tasks, including text classification. However, the context of the transformer’s attention mechanism is limited to single sequences, and their fine-tuning stage can utilize only inductive learning. Focusing on broader contexts by representing texts as graphs, previous works have generalized transformer models to graph domains to employ attention mechanisms beyond single sequences. However, these approaches either require exhaustive pre-training stages, learn only transductively, or can learn inductively without utilizing pre-trained models. To address these problems simultaneously, we propose the Graph Receptive Transformer Encoder (GRTE), which combines graph neural networks (GNNs) with large-scale pre-trained models for text classification in both inductive and transductive fashions. By constructing heterogeneous and homogeneous graphs over given corpora and not requiring a pre-training stage, GRTE can utilize information from both large-scale pre-trained models and graph-structured relations. Our proposed method retrieves global and contextual information in documents and generates word embeddings as a by-product of inductive inference. We compared the proposed GRTE with a wide range of baseline models through comprehensive experiments. Compared to the state-of-the-art, we demonstrated that GRTE improves model performances and offers computational savings up to ~100x.