We are proud to announce the GraphTeacher, which is now published in IEEE Transactions on Artificial Intelligence!
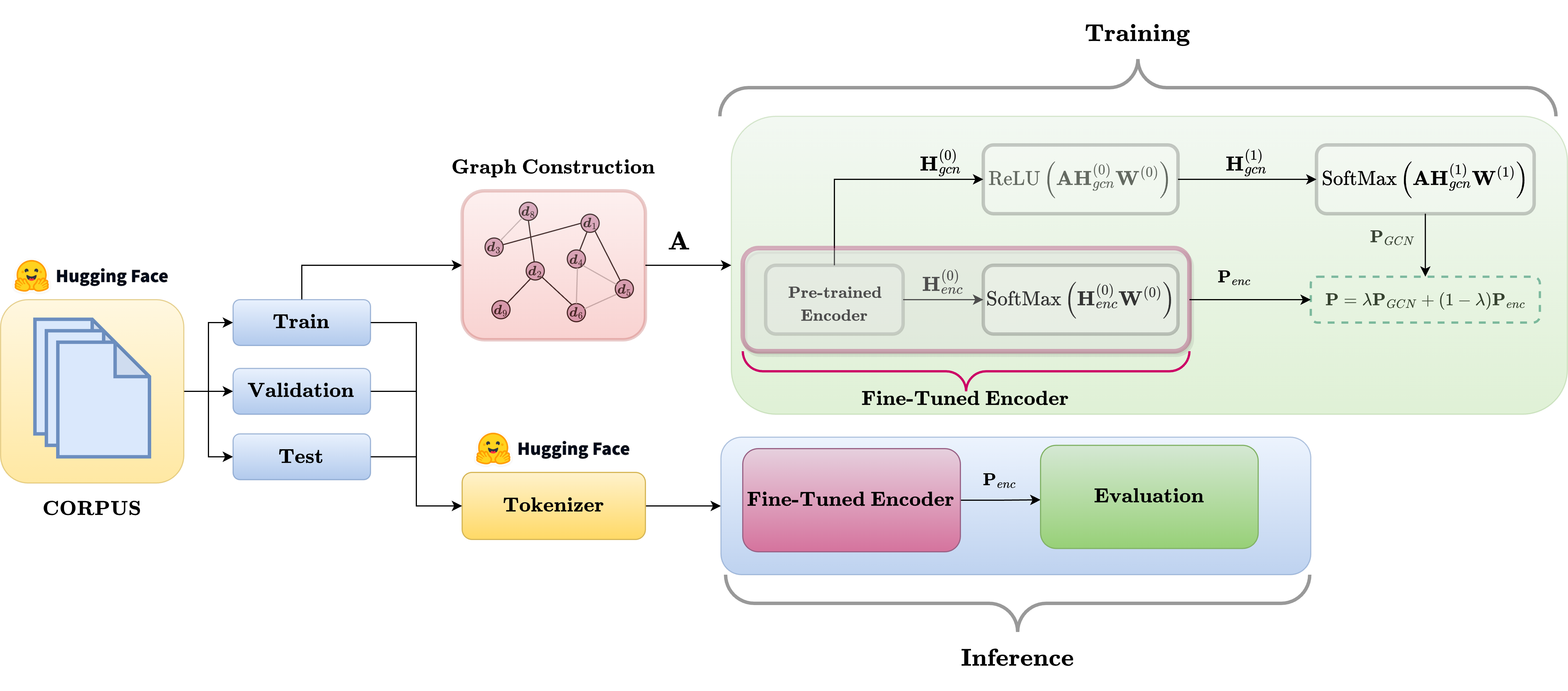
GraphTeacher tackles a core NLP challenge—scarce labeled data—by integrating GNNs into the fine-tuning of transformer encoders to exploit unlabeled data while excluding test nodes from the graph, eliminating re-graphing and enabling inductive, single-instance inference.
🔬 Evaluated on GLUE with BERT, DistilBERT, and RoBERTa across 5–50% labeled data, our approach yields up to +10% over baselines, demonstrating strong scalability, adaptability, and improved generalization/robustness on diverse, graph-structured data—offering an elegant solution to a real-world challenge.
🚀 The contributions of GraphTeacher are summarized below:
● Unlabeled data integration: Fine-tunes transformer encoders by leveraging unlabeled training data for real-world, low-label settings.
● No test nodes in the graph: Excludes test nodes, avoiding re-graphing for new samples and preventing test-time information leakage.
● Inductive inference: Supports efficient single-instance inference, making deployment seamless and scalable.
● Scalable & robust: Works from standard to large-scale corpora and consistently improves performance.
● Model-agnostic GNN boost: Delivers gains across diverse GNN variants and with both custom and pre-built graphs.
For more details and code:
Paper: https://ieeexplore.ieee.org/document/11223233
Code: https://github.com/koc-lab/graph-teacher
Abstract:
We present GraphTeacher for fine-tuning transformer encoders by leveraging Graph Neural Networks (GNNs) to effectively train models when fully labeled training data is unavailable. When different percentages of labeled training data exist, we study popular transformer models, DistilBERT, RoBERTa, and BERT. The proposed approach uses the underlying graph structure of a corpus by allowing the transformer encoders to incorporate GNNs into the fine-tuning process. Using latent patterns and correlations identified in unlabeled data, our method aims to enhance the model’s adaptability to scarcely labeled data scenarios. Moreover, our approach excels in conducting single-instance inference, a capability not inherently possessed by models with a transductive (semi-supervised) training stage. GraphTeacher not only processes the unlabeled data effectively, as in transductive methods, but also offers an inductive inference setup for test samples. Experiments on diverse datasets and various GNN architectures show that integrating GNNs significantly enhances transformer encoders’ robustness and generalization capabilities, in particular under sparsely labeled training conditions. GraphTeacher demonstrates a noteworthy improvement, achieving up to a 10% increase in performance on the GLUE benchmark dataset compared to the baselines.