The work of Dr. Koç and his collaborators on sentiment analysis has been published in IEEE Transactions on Neural Networks and Learning Systems.
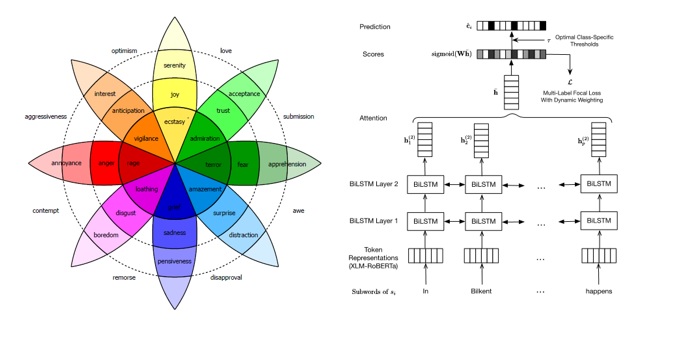
The paper entitled “Multi-Label Sentiment Analysis on 100 Languages with Dynamic Weighting for Label Imbalance” proposes a novel method to overcome the inherent label imbalance problem in multi-label classification by balancing losses from different classes. The proposed model can classify sentiment in 100 different languages and achieves first place in 7 of 9 metrics in English, Arabic and Spanish languages in the SemEval competition using only a single model.
The paper can be accessed [here].
Abstract:
We investigate cross-lingual sentiment analysis, which has attracted significant attention due to its applications in various areas including market research, politics, and social sciences. In particular, we introduce a sentiment analysis framework in multi-label setting as it obeys Plutchik’s wheel of emotions. We introduce a novel dynamic weighting method that balances the contribution from each class during training, unlike previous static weighting methods that assign non-changing weights based on their class frequency. Moreover, we adapt the focal loss that favors harder instances from single-label object recognition literature to our multi-label setting. Furthermore, we derive a method to choose optimal class-specific thresholds that maximize the macro-f1 score in linear time complexity. Through an extensive set of experiments, we show that our method obtains the state-of-the-art performance in seven of nine metrics in three different languages using a single model compared with the common baselines and the best performing methods in the SemEval competition. We publicly share our code for our model, which can perform sentiment analysis in 100 languages, to facilitate further research.