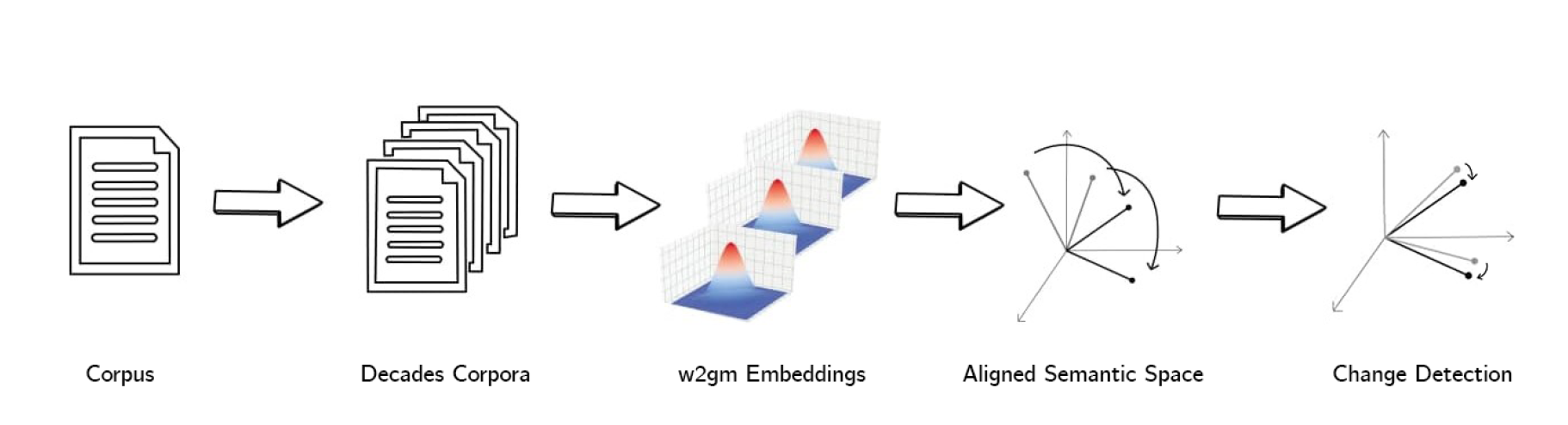
To tackle the problem of lexical semantic change, KocLab has developed the first Gaussian word embedding (w2g)-based approach, which has been described in the paper “Semantic Change Detection with Gaussian Word Embeddings” published at IEEE Transactions on Audio, Speech and Language Processing. The proposed method reached high rankings (including the first rank at one of the two sub-tasks) at the SemEval 2020 Task 1, which is the standardized evaluation framework of the field.
Languages evolve with time since cultural and linguistic effects alter meanings of words in a semantic space and diachronic study of semantic change explores those changes in word meanings. Computationally detecting and analyzing lexical semantic change are of fundamental importance since, let alone the theoretical importance for computational semantics and linguistics, identifying semantically altered words improves the performances of a wide range of high-level NLP applications.
KocLab makes a significant contribution to the field of lexical semantic change detection by proposing this theoretically motivated approach utilizing w2g embeddings that results in high correlation with human judgements. In addition to modelling relative positions of words within semantic vector spaces, the variance components of w2g embeddings model semantic coverages of words. This aspect of w2g-based models provides crucial information since semantic change occurs not only as a drift of meaning within semantic space but also as narrowing or broadening of semantic coverage.
With the successful introduction of w2g-based models to the diachronic NLP studies, we expect to see future efforts exploring ways to exploit word variances in LSC detection and categorization.
The paper can be accessed [here].
Abstract:
Diachronic study of the evolution of languages is of importance in natural language processing (NLP). Recent years have witnessed a surge of computational approaches for the detection and characterization of lexical semantic change (LSC) by using advancing word representation techniques and the availability of diachronic corpora. We propose a Gaussian word embedding (w2g) based methodology and present a comprehensive study for the LSC detection. W2g is a probabilistic distribution-based word embedding model and represents words as Gaussian mixture models using covariance information along with the existing mean (word vector). We also extensively study several aspects of w2g-based LSC detection under the SemEval-2020 Task 1 evaluation framework as well as using Google N-gram corpus. In the Sub-task 1 (LSC binary classification) of the SemEval-2020 Task 1, we report the highest overall ranking as well as the highest ranks for the two (German and Swedish) of the four languages (English, Swedish, German and Latin). We also report the highest Spearman correlation in the Sub-task 2 (LSC ranking) for Swedish. Our overall rankings in the LSC classification and ranking sub-tasks are 1st and 7th, respectively. Qualitative analysis has also been presented.